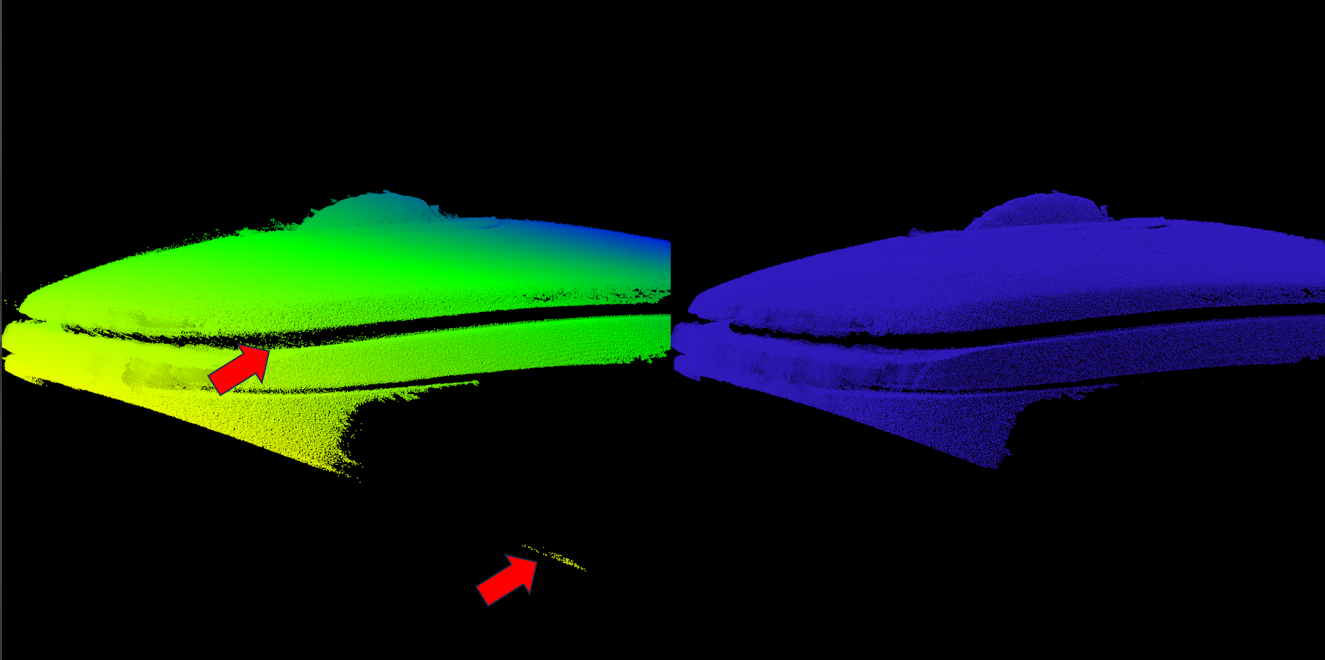
一、点云密度介绍
点云密度反应了点云的密集程度和分布,是点云的重要特征信息;其与采集设备的分辨率,被采集物体的表面材料有关。
广义上的点云密度有两种方法表示:
①距离密度,即给定需要计算点的数量,统计每个邻近点到该点的距离作为密度;
②点密度,即给定邻域半径,统计该点领域半径内的点数量作为点密度。
二、具体实现
主要步骤如下:
- 指定搜索半径
radius和最小点密度阈值minPts。可以先用cloudcompare查看
- 用
radiusSearch统计种子点的在radius局部点的数量,作为点的密度值densiities。
- 遍历每个点的密度,满足密度阈值的点放入点集中。
2.1指定搜索半径和密度阈值
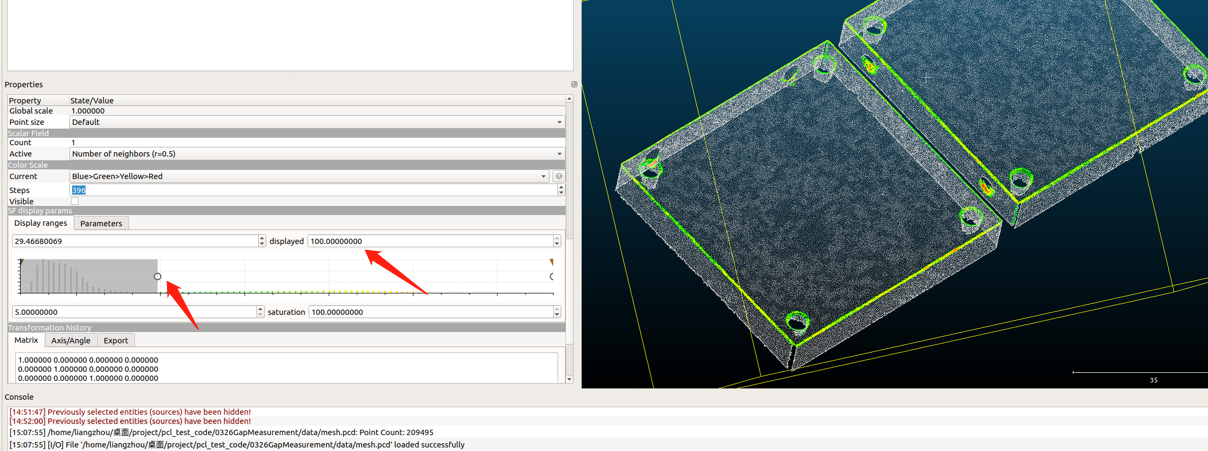
这一步可以指定搜索半径和阈值,可以把点云文件导入cloudcompare内查看,以便设置更合适的阈值。
- 导入文件–>Tools–>Other–>Compute geometric features
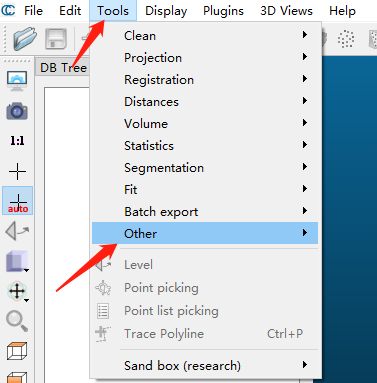
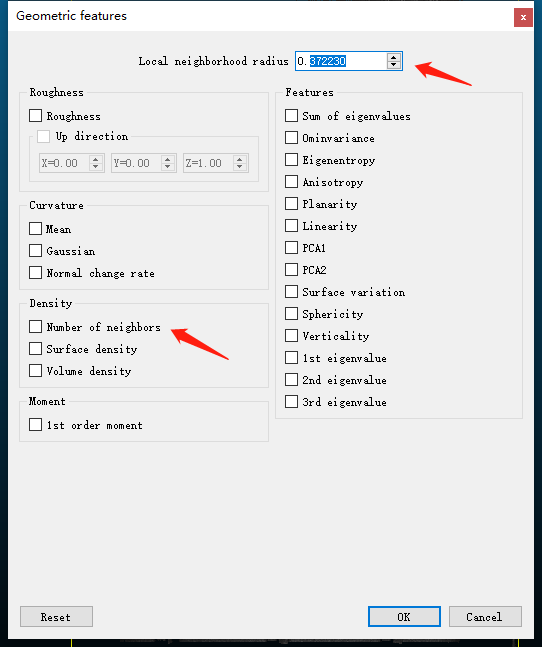
- 设置半径和勾选要计算的特征即可,这里我们勾选局部邻域内点的数量作为密度。
2.2计算点的局部密度
首先构建kdtree,使用kdtree中的radiusSearch函数搜索种子点指定半径内点的索引nn_indices,然后将nn_indices.size()作为局部密度赋值给densiities。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
float radius=0.8;
int minPts=90;
pcl::search::KdTree<pcl::PointXYZ>::Ptr treedense (new pcl::search::KdTree<pcl::PointXYZ>);
treedense->setInputCloud(cloud);
std::vector<int> nn_indices;
std::vector<float> nn_dists;
std::vector<float> densiities(cloud->size(),0);
for (size_t i = 0; i < cloud->size(); i++){
treedense->radiusSearch(i,radius,nn_indices,nn_dists);
densiities[i]=nn_indices.size();
}
|
2.3筛选点并进行聚类
创建visited用于记录点是否已经访问过,当点已经被访问过,或点的密度小于阈值则跳过该点。然后创建一个队列queue用于记录当前聚类的点,queue为先入先出结构。最后得到点云满足阈值条件的的密度聚类cluster。将其放入clusters中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| std::vector<bool>visited(cloud->size(),false);
for (size_t i = 0; i < cloud->size(); i++)
{
if (visited[i] || densiities[i] < minPts)
{
continue;
}
pcl::PointCloud<pcl::PointXYZ> cluster;
std::vector<int>singlegapindices;
std::queue<int>q;
q.push(i);
visited[i]=true;
while (!q.empty())
{
int idx =q.front();
q.pop();
cluster.push_back((*cloud)[idx]);
singlegapindices.push_back(idx);
std::vector<int> n_indices;
std::vector<float> n_dists;
treedense->radiusSearch(idx, radius, n_indices, n_dists);
for (size_t j = 0; j < n_indices.size(); j++)
{
int neighbor_idx = n_indices[j];
if (!visited[neighbor_idx] && densiities[neighbor_idx] >= minPts)
{
q.push(neighbor_idx);
visited[neighbor_idx] = true;
}
}
}
clusters.push_back(cluster);
|
2.4代码
总的实现代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
| void SegByLocalDensity(const pcl::PointCloud<pcl::PointXYZ>::Ptr &cloud,
std::vector<pcl::PointCloud<pcl::PointXYZ>>& clusters,
std::vector<std::vector<int>>& gappointindices)
{
float radius=0.8;
int minPts=90;
pcl::search::KdTree<pcl::PointXYZ>::Ptr treedense (new pcl::search::KdTree<pcl::PointXYZ>);
treedense->setInputCloud(cloud);
std::vector<int> nn_indices;
std::vector<float> nn_dists;
std::vector<float> densiities(cloud->size(),0);
for (size_t i = 0; i < cloud->size(); i++)
{
treedense->radiusSearch(i,radius,nn_indices,nn_dists);
densiities[i]=nn_indices.size();
}
std::vector<bool>visited(cloud->size(),false);
for (size_t i = 0; i < cloud->size(); i++)
{
if (visited[i] || densiities[i]< minPts)
{
continue;
}
pcl::PointCloud<pcl::PointXYZ> cluster;
std::vector<int>singlegapindices;
std::queue<int>q;
q.push(i);
visited[i]=true;
while (!q.empty())
{
int idx =q.front();
q.pop();
cluster.push_back((*cloud)[idx]);
singlegapindices.push_back(idx);
std::vector<int> n_indices;
std::vector<float> n_dists;
treedense->radiusSearch(idx, radius, n_indices, n_dists);
for (size_t j = 0; j < n_indices.size(); j++)
{
int neighbor_idx = n_indices[j];
if (!visited[neighbor_idx] && densiities[neighbor_idx] >= minPts)
{
q.push(neighbor_idx);
visited[neighbor_idx] = true;
}
}
}
clusters.push_back(cluster);
gappointindices.emplace_back(singlegapindices);
}
|
2.5原始图像

2.6处理后的图像